第1章 第5节 文字接龙(二)-概率分布的数学本质
第1章 第5节 文字接龙(二)-概率分布的数学本质
5.1 阅读指南
上一节展示了ChatGPT如何通过文字接龙逐词预测。本节深入核心问题:这些概率是如何计算出来的。将深入理解概率分布的概念,以及大模型计算每个词概率的完整流程。
5.2 概率分布的本质
用更正式的语言来描述这个过程。
每一步,大模型都在计算一个概率分布。
什么是概率分布?
就是对所有可能的结果,给出每个结果发生的概率。就像天气预报说:"明天有40%的概率下雨,30%的概率晴天,20%的概率阴天,10%的概率多云"。把所有可能的天气情况列出来,每种情况都有一个概率,所有概率加起来等于100%。这就是一个概率分布。
ChatGPT做的是计算:在当前上下文中,词表中每一个词作为下一个词出现的概率。
Note
这里说的是"每一个词"——大模型真的会计算词表中所有词的概率(如果词表中有约20万个词,那就是真的计算20万个词的概率)。虽然大部分词的概率接近0%,但每次都要全部计算一遍。这也是为什么大模型需要强大计算能力的原因。
用数学语言表示:
P(下一个词 | 前面所有词)
这个公式读作:
"在给定前面所有词的情况下,下一个词是某个特定词的概率"
具体例子:
假设前面的文字是「今天」「天气」「真」,那么:
- P(好 | 今天、天气、真) = 45%
- P(不错 | 今天、天气、真) = 25%
- P(热 | 今天、天气、真) = 15%
- P(冷 | 今天、天气、真) = 8%
- P(其他词 | 今天、天气、真) = 7%
P(好 | 今天、天气、真) 读作:
"在已知前文是[今天天气真]这五个字的情况下,下一个词是[好]的概率为45%"。
这里只列出了几个候选词作为示例。实际上GPT会计算词表中所有词的概率,所有概率加起来等于100%。
概率的计算过程
这是整个大模型最核心的部分。简单来说:
- 把文字转成数字:每个词变成一串数字(称为"向量")
- 通过Transformer处理:数千亿个参数对这些数字进行复杂计算
- 输出每个词的得分:计算出词表中所有词各自的"原始得分"
- 转换成概率:把得分转换成0-100%的概率,总和为100%
- 从概率中采样:不总选最高概率,而是按概率随机选择
Tip
说明:此处做了简化讲解。
实际的计算过程涉及Embedding、Transformer网络、Softmax等技术细节。对这些"黑箱"内部机制感兴趣的,可以继续往下看详细讲解。不感兴趣的可以跳过下面的技术细节。核心要点在于:数千亿个参数的共同作用,最终输出了那个概率分布。
5.3 技术细节详解
大模型内部如何计算概率分布,需要详细拆解每一步。先看一张整体流程图:
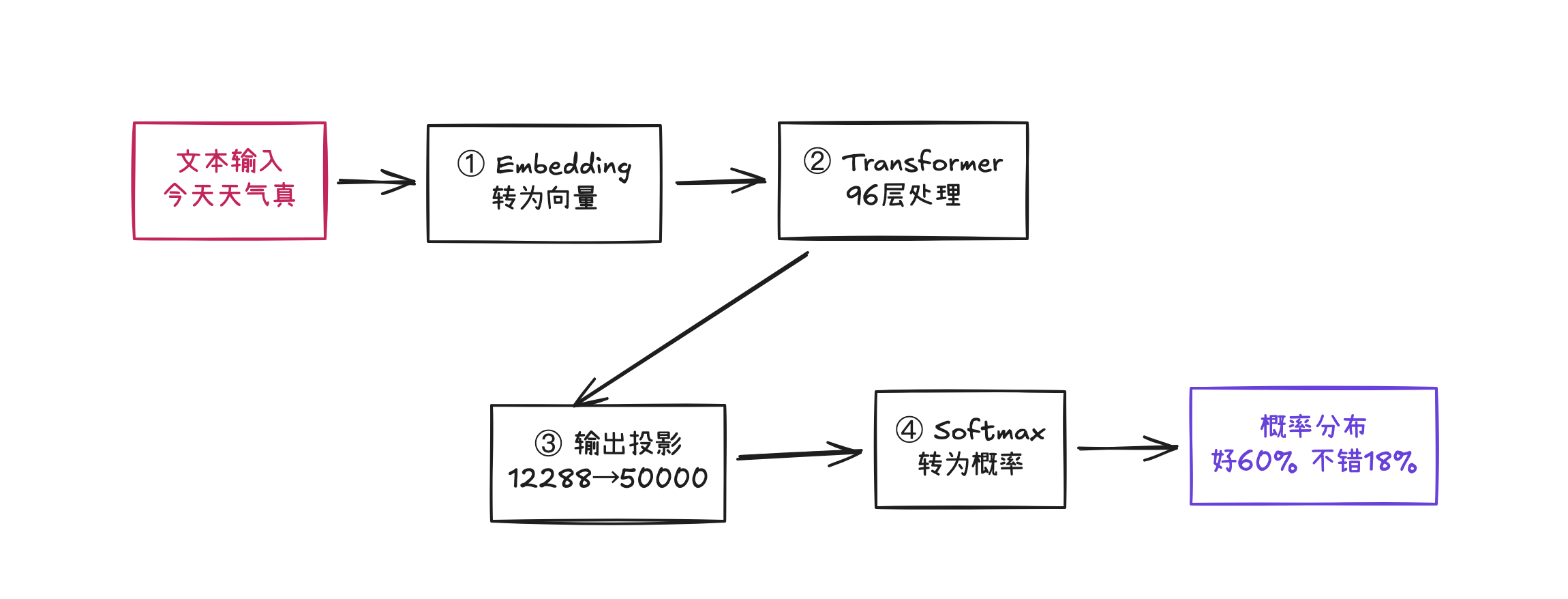
把文字转成向量
计算机不能直接理解文字,所以第一步要把每个词转换成数字。这个过程称为Embedding(词嵌入)。假设需要大模型预测"今天天气真"后面的词,大致流程如下。
首先,每个词被转换成12288维向量(即12288个数字,以GPT-3为例):
"今天" → [0.23, -0.45, 0.67, ..., 0.12] ← 12288个数字
"天气" → [0.34, -0.12, 0.45, ..., 0.23]
"真" → [-0.12, 0.56, -0.34, ..., 0.45]
Tip
不同GPT版本的向量维度:
- GPT-3:12288维
- GPT-4/5:向量维度未公开,可能更大
- 维度越大,理论上能表达的语义信息越丰富
现在输入变成了一个数字矩阵:
[
[0.23, -0.45, ..., 0.12], ← "今天"(12288维)
[0.34, -0.12, ..., 0.23], ← "天气"
[-0.12, 0.56, ..., 0.45] ← "真"
]
通过Transformer逐层处理
GPT有很多层。每一层都在做复杂的数学运算,逐步理解文字的深层含义。不同版本的层数:
- GPT-3:96层
- GPT-4/5:层数未公开,但更深
┌─────────────────────────────────────
│ 输入向量
│ [今天] [天气] [真]
└──────────────┬──────────────────────
│
▼
┌─────────────────────────────────────
│ 第1层:词间关系理解
│ → 理解"今天"和"天气"的关系
└──────────────┬──────────────────────
│
▼
┌─────────────────────────────────────
│ 第2层:词性分析
│ → 理解"天气"是名词,"真"是副词
└──────────────┬──────────────────────
│
▼
┌─────────────────────────────────────
│ 第3层:语义理解
│ → 理解这是在描述天气情况
└──────────────┬──────────────────────
│
▼
╔═══════════╗
║ ... ║ ← 93层深度处理
╚═══════════╝
│
▼
┌─────────────────────────────────────
│ 第96层:信息融合
│ → 综合所有信息,准备预测
└──────────────┬──────────────────────
│
▼
┌─────────────────────────────────────
│ 输出向量
│ [融合了整个句子的语义信息]
└─────────────────────────────────────
每一层都在用数千亿个参数中的一部分,对输入进行变换,逐步提取更深层的语义。
Tip
每一层实际上是Transformer架构中的模块,包含Self-Attention(让词与词"对话")和FFN(前馈网络,进行深度计算)。对Transformer内部机制感兴趣的,可以自行深入学习相关资料。
把最后的向量转换成概率
经过多层变换后(以GPT-3的96层为例),最后一个词("真")对应的向量变成了:
[1.2, -0.8, 2.3, ..., -1.5] ← 仍然是12288维
这个向量包含了"接下来应该说什么"的所有信息。
Note
为什么只用最后一个词("真")的向量?
经过96层Transformer处理后,每个词的向量都已经融合了整个句子的上下文信息。预测"真"后面的词,所以取最后一个词对应的向量来预测。
这个向量不仅包含"真"本身的信息,还通过Self-Attention机制融合了"今天"、"天气"等所有前文的信息。虽然只用了一个向量,但它已经"看到"了整个句子的信息。
如果"真"只包含自己的信息,没有全句的综合信息,一定预测不准。
然后,通过一个叫做“输出投影”的操作,把这个向量变换成词表大小的数字(GPT-3的词表约5万个词):
内部向量(12288个数字)
[1.2, -0.8, 2.3, ..., -1.5]
│
│ 输出投影(数学转换)
▼
变换后(约5万个数字)
[3.2, 1.5, -0.3, ..., 2.1]
↑ ↑ ↑ ↑
好 不错 糟糕 ... 晴朗
变换后的每个数字对应词表中的一个词,数字越大,说明这个词被选中的概率就越大。
Tip
这里只用"真"一个词的向量,就能计算出词表中所有词的概率。
"输出投影"和"数学转换"实际上都是线性代数中的概念——具体来说是矩阵乘法运算。线性代数是人工智能的核心数学基础,大模型内部绝大多数计算都基于矩阵运算。对AI原理感兴趣,强烈建议学习线性代数,它是理解深度学习的关键。没有兴趣也没关系,了解大致脉络以后有需要的时候再研究也不错。
Softmax变成概率
但这些数字(3.2,1.5,-0.3,...)还不是概率,原因有两点:
- 概率必须在0到1之间
- 所有概率加起来必须等于1
所以最后一步,用Softmax函数转换:
词汇 原始得分 Softmax转换 概率
────────────────────────────────────
好 3.2 ██████████ 60%
不错 1.5 ████ 18%
很好 0.8 ██ 10%
糟糕 -0.3 █ 5%
... ... ... ...
────────────────────────────────────
100%
原始得分经过Softmax函数转换为概率:
Softmax的原理很简单:
- 得分越高,概率越大
- 把所有概率归一化,让它们加起来等于1
从概率分布中采样
有了概率分布,大模型怎么选择最终的词?
常见的理解是:总是选概率最高的词(比如"好"60%)。
大模型采用的是随机采样——按照概率分布随机选择。
什么意思?就像转盘游戏:
转盘概率分布
┌─────────────────────
│ 好
│ ██████ │ 60%
│
├─────────────────────
│ 不错 很好
│ ███ ██ │ 18% / 10%
└─────────────────────
│ 糟糕 其他词
│ █ ██ │ 5% / 7%
└─────────────────────
转动转盘,指针停在哪里,就选哪个词。这意味着:
- 大多数时候(60%)会选"好"
- 但有时(18%)也会选"不错"
- 偶尔(10%)会选"很好"
- 极少(5%)甚至会选"糟糕"
Note
为什么不总选最高概率?这样做有什么好处?
这个问题涉及到如何让大模型具有创造性。后面的"为什么每次回答都不一样?"小节会详细讨论。
1750亿个参数的计算结果
从"今天天气真"这五个字,经过:
- Embedding查找
- 96层Transformer变换
- 输出投影
- Softmax归一化
最终得到词表中所有词各自的概率。这个过程在人类看来只是一瞬间,但在计算机内部,是数万亿次浮点运算。
这就是"语言模型建模语言的概率分布"的具体含义。
5.4 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 词嵌入 | Embedding | /ɪmˈbedɪŋ/ | 把词映射为高维向量的过程 |
| 变换器架构 | Transformer | /trænsˈfɔːrmər/ | 基于注意力机制的深度神经网络架构 |
| 自注意力 | Self-Attention | /ˌself əˈtenʃn/ | 让序列中每个词与其他词计算相关性权重 |
| 前馈网络 | Feed-Forward Network (FFN) | /fiːd ˈfɔːwərd ˈnetwɜːk/ | Transformer每层中负责深度变换的全连接子模块 |
| 归一化指数函数 | Softmax | /ˈsɒftmæks/ | 将任意实数向量转换为概率分布 |