第1章 第3节 参数的演化
第1章 第3节 参数的演化
3.1 参数的演化:从"记住答案"到"理解规律"
前面我们讲了训练的原理:模型通过调整参数,让预测越来越准确。但这里有一个关键问题:
模型是在"死记硬背答案",还是真的"学会了语言规律"?
让我用具体例子帮你理解这个区别。
两种学习方式的对比
想象你在学英语:
- 方式一:死记硬背
看到问题:"The cat ___ fish." 记住答案:"eats"
看到问题:"The dog ___ bones." 记住答案:"eats"
看到问题:"The bird ___ seeds." 记住答案:"eats"
你只是把每个问题和答案对应起来,但不知道为什么。
- 方式二:理解规律
看到多个例子后,你逐渐意识到:
- "猫"、"狗"、"鸟"都是动物
- 它们后面用 "eats" 而不是 "eat"
- 这是"第三人称单数加s"的规律
现在遇到新问题:"The rabbit ___ carrots." 你能推断:应该是 "eats",虽然没见过这个具体句子
这两种方式的区别在哪?关键在于泛化能力——死记硬背只能处理见过的问题,而理解规律能应对没见过的新情境。
模型的学习方式:从记忆到泛化
如果你是GPT的设计者,面对数十亿GB的训练文本,你会让模型采用哪种学习方式?
直觉上,方式一似乎更简单——见过什么就记住什么。但实际上,这条路根本走不通:
为什么死记硬背行不通?主要有三个原因:
- 训练数据太庞大
数十亿GB的文本,包含无数种表达方式,即使1750亿个参数也记不住每个句子。 - 见过的永远是有限的
互联网有无穷多的新表达,用户的提问千奇百怪,死记硬背只能应付训练集。 - 泛化才是真正的智能
人类不是记住每个句子,而是掌握了语言的规律,模型也必须这样做。
所以,GPT别无选择,只能采用方式二——理解规律。
换句话说:参数存储的不是答案,而是知识。
知识是抽象的规律,答案只是规律的具体体现。模型学会了规律,就能应对无穷变化的问题——这才是真正的智能。这也是为什么ChatGPT或者同类大模型感觉很聪明的原因。
参数演化的实例:从随机到规律
让我用一个具体例子展示这个过程。
假设有一组参数负责处理"动物吃什么"的关联:
阶段1:训练开始
参数组 = [0.0123, -0.0456, 0.0789, ...](随机值)
模型不知道任何关联
阶段2:累计遇到第1000次"猫-鱼"关联(如"猫吃鱼""猫喜欢鱼"等各种表述)
参数组 = [0.0125, -0.0454, 0.0791, ...]
微调了一点点,但还是看不出规律
阶段3:累计遇到第10万次各种动物吃东西的例子("猫吃鱼""狗吃骨头""鸟吃种子""猫抓了一条鱼"...)
参数组 = [0.0345, -0.0234, 0.1567, ...]
模型开始"意识到":动物和食物之间有关联
阶段4:累计遇到第100万次
参数组 = [0.2567, -0.1234, 0.4321, ...]
模型已经"学会"了规律:
• 看到"猫",会想到"鱼"
• 看到"狗",会想到"骨头"
• 甚至遇到没见过的动物,也能推测其食物
阶段5:训练结束
参数组 = [0.3124, -0.0987, 0.5678, ...](稳定下来)
这些参数现在编码了"动物-食物"的语义关联
Note
补充说明:什么是"累计遇到1000次"?
这里的"1000次"不是指连续1000次出现同一个句子,而是指:
在整个训练过程中,模型累计遇到了1000次包含"猫-鱼"这种语义关联的文本。
这些文本可能是各种不同的表述:
- "猫吃鱼"
- "猫喜欢吃鱼"
- "小猫咪正在吃一条鱼"
- "这只猫抓了一条鱼"
- "猫的食物通常是鱼"
- ...
而且这些文本分散在整个训练数据集的不同位置,不是连续出现的。
参数不是记住了"猫→鱼"这个答案,而是学会了"动物与其食物之间有关联"这个规律。
训练完成:参数固化
经过数周的训练,花费数百万美元的算力,1750亿个参数终于稳定下来。
这时,训练停止,参数被"冻结":
参数₁ = 0.2341 ← 固定了
参数₂ = -0.5678 ← 固定了
...
参数₁₇₅₀₀₀₀₀₀₀₀₀ = 0.8901 ← 固定了
这就是我们今天使用的ChatGPT。
当你问它问题时,它不会再调整参数,而是用这1750亿个已经训练好的参数,计算你的问题的答案。就像一个学生读完了所有的书,考试结束了,知识已经内化在脑海里,不会再变了。
3.2 黑箱问题:没有人知道每个参数的含义
这里有一个有趣的事实:
虽然我们知道这1750亿个参数存储了语言知识,但没有人能确切地说出每个参数代表什么。
这些参数是通过训练"自然涌现"出来的,而不是人工设计的。我们能看到整体的效果(ChatGPT能流畅对话),但很难解释局部的机制(为什么参数₂₃₄₅₆₇这个位置恰好是0.5678这个值)。
让我深入探讨一下这个"不可解释性"问题,因为它触及了现代AI的一个根本性困境。
人类创造了自己也不完全理解的工具
你问一个AI工程师:"为什么ChatGPT对这个问题给出这样的答案?"
工程师:"因为那1750亿个参数经过计算,产生了这个答案。"
你:"为什么是这个答案?"
工程师:"因为参数是这样设置的。"
你:"为什么参数是这样设置的?"
工程师:"因为训练数据和优化算法让它收敛到这个状态。"
你:"但具体哪个参数负责哪部分逻辑?"
工程师:"……我们不知道。"
这不是开玩笑。我们真的不知道每个参数到底在做什么。具体来说,我们无法精确地回答:
- 参数₂₃₄₅₆₇为什么是0.5678而不是0.5679
- 这个参数具体编码了什么知识
- 修改这个参数会导致什么变化
为什么会这样?关键在于知识的分布式存储。"猫吃鱼"这个知识,不是存储在某一个参数里,而是存储在可能数百万个参数的组合中:
参数₁₂₃ = 0.23 ┓
参数₄₅₆ = -0.45 ┃
参数₇₈₉ = 0.67 ┣━━ → 这些参数的组合
... ┃ 共同编码了"猫-鱼"关系
参数₉₉₉₉ = 0.12 ┛
就像全息图:每一小块都包含整幅图像的信息,但都很模糊;只有组合起来,才能看清完整的图像。
与人类大脑的惊人相似
这让我想起人类大脑的一个有趣对比:
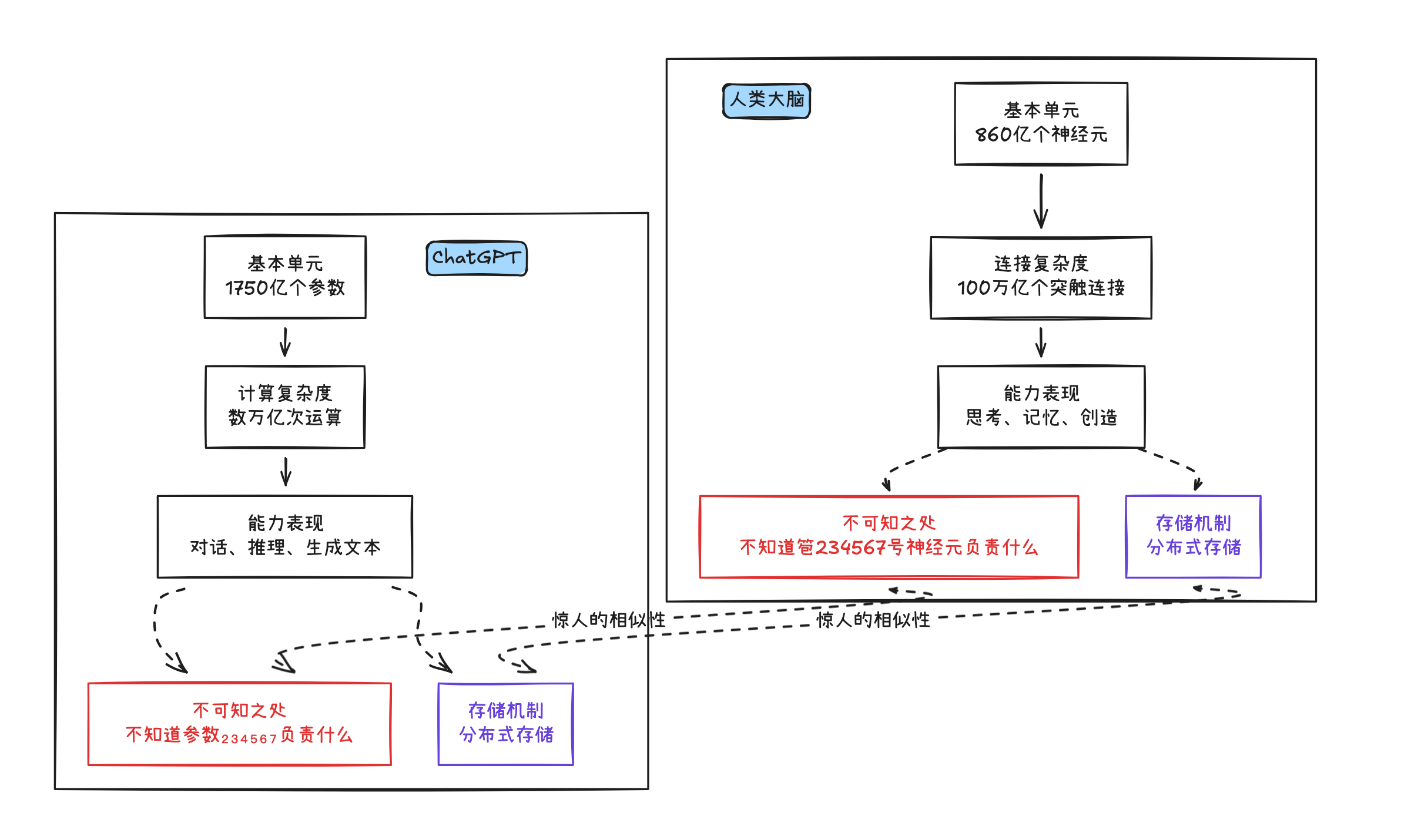
这个相似性,是巧合吗?还是说,分布式表示是智能系统的必然特征?
不可解释性的后果
这种不可解释性,带来了深刻的问题:
- 安全性问题
如果我们不知道模型"为什么"这样回答?
我们怎么确保它不会给出危险的建议?
我们怎么预防它被恶意利用?
- 可信度问题
在医疗、法律等关键领域:
"这个AI说这个病人需要手术"
医生:"为什么?"
AI:"我的1750亿个参数计算出来的"
医生:"……" ← 敢相信吗?
- 调试困难
当模型出错时:
传统软件:可以定位到具体哪一行代码有bug
ChatGPT:是1750亿个参数中的哪些出了问题?无从查起
可解释AI:尝试打开黑箱
正因为这个问题如此重要,"可解释AI"(Explainable AI, XAI)成为了一个热门研究领域。
研究者们在尝试:
- 机制解释:理解Transformer内部的计算流程
- 特征可视化:把抽象的参数变成人类能理解的概念
- 因果分析:找出"哪些输入导致了哪些输出"
但坦白说,进展缓慢。1750亿个参数的复杂性,可能已经超出了人类完全理解的能力边界。
我们理解自己的思维过程吗?
当你读到这里,决定"嗯,这个例子很好理解",这个判断是怎么在你脑海中形成的?你能说出具体是哪860亿个神经元中的哪些,以什么方式产生了这个想法吗?
不能。
人类的思维,对人类自己来说,也是一个黑箱。我们能感受到思维的结果,但很难追溯思维的过程。
也许,"理解"本身就有层次:
- 使用层面的理解:我知道怎么用它 ✓
- 功能层面的理解:我知道它能做什么 ✓
- 机制层面的理解:我知道它为什么这样工作 ?
- 原子层面的理解:我知道每个部件的精确作用 ✗
对ChatGPT,我们有前两层的理解,但第三第四层很模糊。对人脑,我们也是如此。这或许说明:复杂智能系统,必然带有某种程度的不可解释性。
而我们,正在学习与这种不确定性共处——既利用AI的强大能力,又警惕它的不可预测性。
3.3 关于大模型参数数量:一个持续增长的天文数字
我们一直在说"1750亿个参数",这里需要明确说明一下:
1750亿是GPT-3的参数量,这是在2020年公开的数据。而现在你用的ChatGPT,已经升级到了GPT-5.5(2026年4月发布),参数量已经远超这个数字。
GPT-5.5是OpenAI迄今最智能的模型,核心突破在于大幅升级的Agent智能体能力,能精准理解用户模糊指令,自主规划、调用工具完成复杂任务。
未来,这个数字可能还会继续增长。但无论数字多大,本质不变:它们都是用参数存储知识,通过训练学习语言规律的函数。
各代GPT模型的参数量
GPT-1 (2018): 1.17亿参数
GPT-2 (2019): 15亿参数 ← 增长13倍
GPT-3 (2020): 1750亿参数 ← 增长117倍
GPT-3.5 (2022): 未公开(估计1750亿左右)
GPT-4 (2023): 未公开
GPT-5 (2025): 未公开
GPT-5.1 (2025.11): 未公开
GPT-5.5 (2026.04): 未公开(最新旗舰)
为什么OpenAI不公开新版本的参数量?
从GPT-4开始,OpenAI就不再公布参数量了。官方解释是:
- 竞争原因:参数量是核心竞争力,不想被竞争对手知道
- 安全考虑:避免恶意攻击者利用模型结构信息
根据一些分析和泄露信息:
- GPT-4估计: 1万亿-10万亿参数
- GPT-5/5.1: 完全未知,可能更多,也可能优化了架构
- GPT-5.5: 完全未知(2026年4月发布,核心突破在Agent能力)
大模型参数量对比与符号解释
Google:
├─ PaLM (2022): 5400亿参数
├─ PaLM 2 (2023): 未公开
├─ Gemini Ultra (2024): 未公开
├─ Gemini 2.5 (2025): 未公开
└─ Gemini 3 Pro (2025): 未公开
Anthropic:
├─ Claude 3 (2024): 未公开
├─ Claude 4 (2025): 未公开
└─ Claude Opus 4.5 (2025): 未公开(旗舰)
国内:
├─ 阿里通义千问:
│ ├─ Qwen3-Max (2025): 超万亿参数(旗舰)
│ ├─ Qwen3-235B (MoE): 总参数2350亿,激活220亿
│ ├─ Qwen3-Next (2025): 总参数800亿,仅激活30亿
│ ├─ Qwen3.5-Plus: 多模态,速度更快
│ └─ Qwen3.6系列 (2026): Max/Plus/Flash
│
├─ DeepSeek:
│ ├─ DeepSeek-V3 (2024): 总参数6710亿
│ ├─ DeepSeek-V3.2 (2025): 总参数6850亿
│ ├─ DeepSeek-V4-Pro (2026): 总参数1.6万亿,每token激活490亿(开源旗舰)
│ └─ DeepSeek-V4-Flash (2026): 总参数2840亿,每token激活130亿(高效开源)
│
└─ 智谱:
├─ GLM-4 (2024): 未公开
└─ GLM-5 (2026): 未公开
目前,除了DeepSeek还在坚持全模型版本开源,其他大模型都或多或少呈现初了闭源的趋势,比如阿里的Qwen,Qwen 3.6 Plus,就没有开源了。
商业模型一般都不会公布参数的具体数量;只有开源的模型可以确切的知道其参数数量。
模型命名中的参数量标识
在大模型领域,我们经常看到这样的命名:
Qwen3-235B
Llama-70B
GPT-3 (175B)
这些B、M、T是什么意思?
这是参数数量的国际通用缩写:
M (Million) = 百万 = 10⁶ = 1,000,000
B (Billion) = 十亿 = 10⁹ = 1,000,000,000
T (Trillion) = 万亿 = 10¹² = 1,000,000,000,000
换算示例:
117M = 117百万 = 1.17亿参数
70B = 70十亿 = 700亿参数
175B = 175十亿 = 1750亿参数
235B = 235十亿 = 2350亿参数
1.8T = 1.8万亿 = 1万8千亿参数
所以:
- Qwen3-235B 表示这个模型有 2350亿个参数
- Llama-70B 表示这个模型有 700亿个参数
- GPT-3 (175B) 表示这个模型有 1750亿个参数
模型架构:Dense vs MoE
在很多模型列表中,有些模型标注了"MoE"(比如我们前面列举的一些模型),有些是"Dense"。这是两种不同的架构设计。作为程序员,我们未必需要深入了解具体的架构,但需要知道他们的大致概念。
Dense架构(传统架构)是最常见的架构,GPT-3、GPT-4、Claude都采用这种方式:
- 每次推理使用全部参数
- 比如GPT-3有1750亿参数,每次回答问题都要用到全部1750亿
MoE架构(混合专家模型)则是一种更高效的设计。MoE全称Mixture of Experts(混合专家模型):
- 模型包含多个"专家"子网络
- 每次推理只激活部分专家
- 不同问题激活不同专家
举例对比、
Qwen3-235B (MoE, 2025):
总参数:2350亿
实际激活:约220亿
优势:速度接近220亿参数的模型,但能力接近2350亿
Qwen3-Next (MoE, 2025):
总参数:800亿
实际激活:仅30亿
优势:极致效率,用极小激活参数实现旗舰级性能
DeepSeek-V3 (MoE, 2024):
总参数:6710亿
实际激活:约370亿
优势:超大参数量,但推理成本可控
DeepSeek-V4-Pro (MoE, 2026):
总参数:1.6万亿
实际激活:约490亿
优势:万亿级开源旗舰,性能逼近顶级闭源模型
DeepSeek-V4-Flash (MoE, 2026):
总参数:2840亿
实际激活:约130亿
优势:极致高效,用更少激活参数实现强大性能
两种架构各有优势
MoE的优劣势:
优势:
- 参数量大,能力强
- 推理时只激活部分参数,速度快
- 计算成本和内存占用相对可控
劣势:
- 训练复杂度高,需要精心调优专家路由
- 不同专家可能学到不均衡的知识
- 对某些问题可能比Dense模型表现差
Dense的优劣势:
优势:
- 架构成熟,训练稳定
- 所有参数协同工作,整体性强
- 不需要复杂的专家路由机制,实现简单
- GPT-4、Claude等顶级模型都采用Dense架构
劣势:
- 推理时必须使用全部参数,计算量大
- 相同参数量下,推理速度比MoE慢
- 内存占用高,部署成本更高
3.4 冷知识与趣闻
冷知识1:ChatGPT并不会因为你的使用而变聪明
很多人以为ChatGPT会"学习"你的对话,变得越来越聪明。
真相是:完全不会。
ChatGPT的生命周期分两个阶段:
阶段一:训练(OpenAI完成,只做一次)
│
├─ 用3000亿个词训练模型
├─ 调整那1750亿个参数 ✓
└─ 训练完成,参数"冻结" ✓
阶段二:使用(你每天用的ChatGPT)
│
├─ 你问问题
├─ ChatGPT用固定的1750亿参数计算 ✓
├─ 输出答案
└─ 参数完全不变 ✗ 不会调整
当GPT-3训练好后,那么他的参数就"冻结"了;GPT-4则需要重新再训练。
这解释了为什么:
- ChatGPT不会记住你之前的对话
- 参数固定,不存储新信息
- 每次对话都是独立的(除非在同一个会话中,这涉及到上下文,我们后面会讨论,但模型本身是没有记忆能力的)
- ChatGPT不会学习新知识
- 参数固定,不会更新
- 知识截止日期是训练时的数据截止日期
- 你今天用和明天用,ChatGPT完全一样
- 1750亿个参数一个不变
- 除非OpenAI发布新版本(那是全新的模型)
那OpenAI会不会优化参数?
- ✗ 不会微调老模型:GPT-3训练完就固定了
- ✓ 会训练新模型:GPT-4有更多参数,更强能力
- ✗ 用户对话不改变模型:你的使用不会调整参数
- ✓ 会发布新版本:但那是全新的模型,不是调整老模型
如果ChatGPT真的能从每个用户的对话中学习,全球每天数亿次对话,每次都要实时调整那1750亿个参数,计算量和成本都会是天文数字,完全无法承受!
所以,参数固定不仅是设计选择,也是工程必须。
Tip
你可以问任何一个大模型:你的训练数据截止日期是什么时候?
目前,大部分的模型训练日期都在2024~2025年。他们的共性就是会落后于当前时间。
冷知识二:参数越多越好?没那么简单
很多人以为:参数越多,模型就越聪明。
但参数太多也会带来麻烦。
一个班级的学生从30人增加到300人:
- 每个人都需要座位 → 教室要大10倍
- 每个人都需要吃饭 → 食堂要大10倍
- 每个人都需要考试 → 改卷时间长10倍
参数也是一样:
- 训练成本爆炸
- GPT-2 (15亿参数): 训练花费 约几万美元
- GPT-3 (1750亿参数): 训练花费 约500万美元
- GPT-4 (未公开): 训练花费 估计上亿美元
参数量每增长一个数量级 → 成本可能增长10-100。
- 推理速度变慢
参数多 = 计算量大 = 回答得慢
这就是为什么GPT-4比GPT-3.5慢,同样的问题,GPT-4要"思考"更久
- 容易"死记硬背"
参数太多 = 记忆力太好,反而成了坏事
想象你准备数学考试:
理解规律(好学生):
见过:3 + 5 = 8
推广:a + b = b + a (加法交换律)
新题:99 + 1 = ? → 轻松解答
死记硬背(参数过多的模型):
背下:3+5=8,4+6=10,7+2=9……
记忆:把见过的10000道题答案都背下来
新题:99 + 1 = ? → 没背过,不会做!
这就是"过拟合":模型记住了训练数据的每个细节,但没学会背后的通用规律,遇到新情况就傻眼了。
那为什么还要做大模型?因为语言太复杂了,小模型确实应付不来。但最近出现了一个新的趋势:
新思路:"小而精"模型
例如 LLaMA 2 (70亿参数), Mistral (7.3亿参数):
- 参数少,训练快,运行快
- 但通过更好的训练方法,能力也不差
- 普通电脑都能跑起来
- LLaMA 2 70B 甚至能接近 GPT-3.5 的能力
不是参数越多越好,而是要找到"恰到好处"的平衡点——既能干活,又不太费钱费电。
3.5 下一节预告
现在你已经知道:ChatGPT是一个拥1750亿个参数的函数,通过训练学会了语言规律。
但它具体是怎么工作的?当你问它一个问题,它是怎么生成这些答案的?
答案就在下一节:文字接龙游戏。
3.6 扩展阅读
Language Models are Few-Shot Learners (GPT-3论文, 2020)
OpenAI发布的GPT-3官方论文,详细介绍了1750亿参数模型的训练过程、能力表现和局限性。论文展示了当参数量从15亿(GPT-2)跃升到1750亿(GPT-3)时带来的质变。虽然有一定技术深度,但配有大量实例,能让你从第一手资料理解"规模为什么重要"。
3.7 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 参数 | Parameter | /pəˈræmɪtər/ | 模型中的可调整变量,训练后冻结固定 |
| 泛化 | Generalization | /ˌdʒenrəlaɪˈzeɪʃən/ | 从训练数据学习规律并应用到新数据的能力 |
| 过拟合 | Overfitting | /ˌoʊvərˈfɪtɪŋ/ | 模型过度记忆训练数据细节而丧失泛化能力 |
| 分布式表示 | Distributed Representation | /dɪˈstrɪbjuːtɪd ˌreprɪzenˈteɪʃən/ | 知识分散存储在多个参数的组合中,非单个参数独立编码 |
| 推理 | Inference | /ˈɪnfərəns/ | 用训练好的模型对新输入进行计算并输出结果 |
| 黑箱问题 | Black Box Problem | /blæk bɑːks ˈprɑːbləm/ | 难以解释模型内部决策过程的困境 |
| 可解释AI | Explainable AI (XAI) | /ɪkˈsplænəbl eɪ aɪ/ | 旨在让AI决策过程可理解的研究领域 |
| 参数冻结 | Parameter Freezing | /pəˈræmɪtər ˈfriːzɪŋ/ | 训练完成后固定参数不再更新的过程 |
| Dense架构 | Dense Architecture | /dens ˈɑːrkɪtektʃər/ | 每次推理使用全部参数的模型架构 |
| MoE | Mixture of Experts | /ˈmɪkstʃər əv ˈekspɜːrts/ | 混合专家模型,每次推理只激活部分参数的架构 |